사내에 마땅한 모니터링 도구가 없었다.
그래서 모니터링을 도입하자! 라고 건의하니 그럼 너가해라! 라는 평범한 플로우로 흘러갔다
늘 이런 새로운 도전은 스트레스와 성취를 동반한다.
우선 나는 프로메테우스와 그라파나를 중점적으로 살펴보았다.
그렇게 해서 아래와 같은 결과가 나왔다.
- 필요성
- 현재 사내에 서비스 이상 감지를 할 수 있는 수단이 없어 장애 대응의 신속성이 떨어짐
- 서비스 현황을 참고하여 사용량 이상 구간을 사전에 탐지 예방하기 위함
- RDS 및 서비스의 사용량을 추산하여 사용량을 조정하여 지출 비용 감소
- 설계 방향
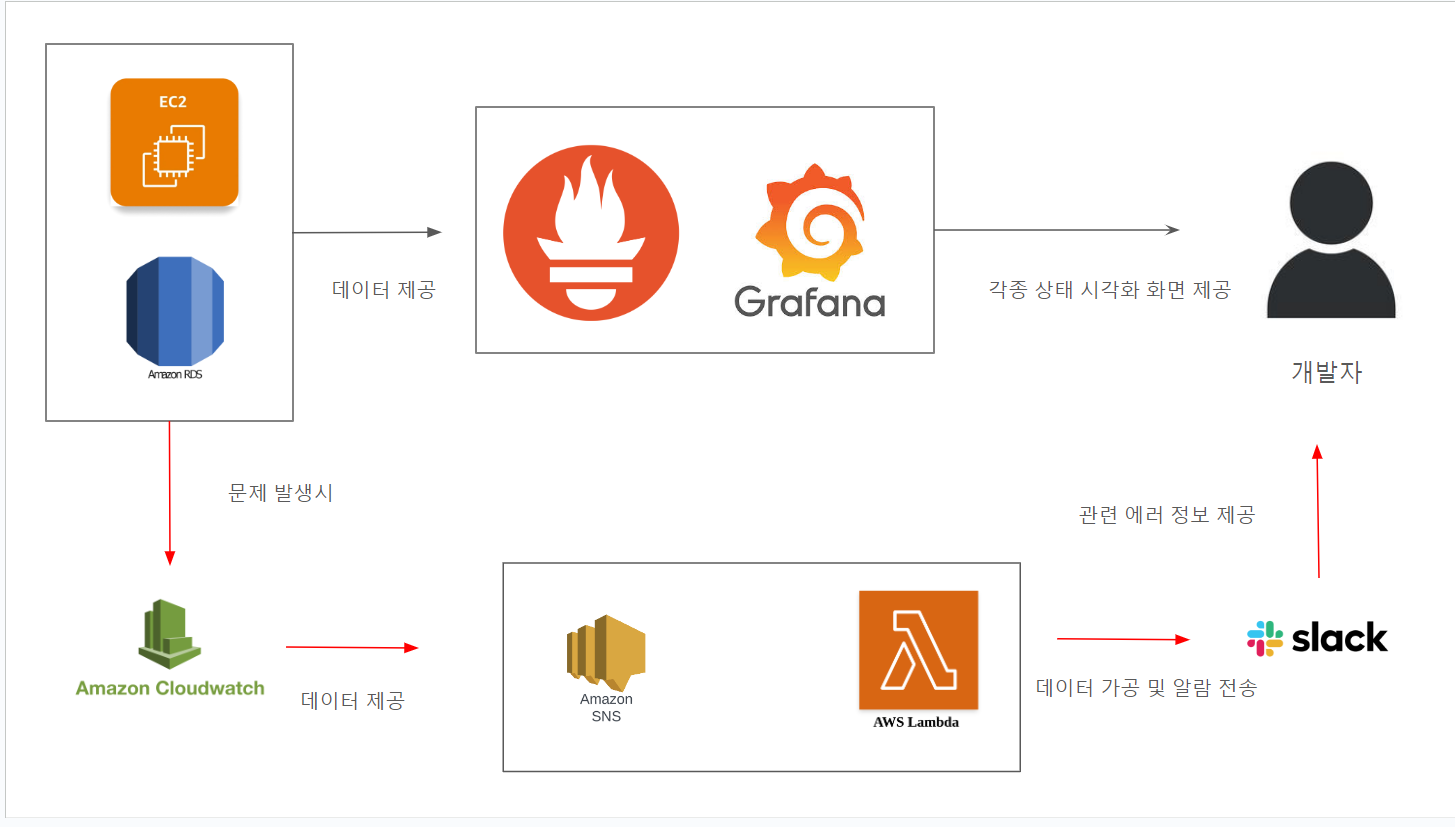
위 설계를 하게된 이유는 아래와 같습니다
- 우리는 시스템 간의 결속력 혹은 의존성이 떄론 장점이 되지만 떄로는 단점이 된다는 사실을 알고있다 그런 관점에서 볼때 이러한 시스템은 뛰어난 작동 보장성을 담보받아야한다. 즉 모니터링 시스템이 잘못되어도 알람은 어떤 경우에도 와야하며, 알람시스템이 잘못되어도 모니터링 시스템은 가동해야한다
장점
- 독립성: 모니터링과 알람 시스템이 독립적으로 운영되기 때문에 한 시스템에 문제가 발생해도 다른 시스템은 영향을 받지 않습니다. 이는 시스템의 신뢰성을 높입니다.
- 유연성: 각각의 시스템이 자신들의 강점을 최대한 활용할 수 있습니다. Prometheus-Grafana는 강력한 모니터링과 시각화를 제공하고, AWS CloudWatch는 알람 설정과 자동화된 대응을 지원합니다.
- 확장성: 각 시스템이 독립적으로 확장 가능하며, 필요에 따라 모니터링이나 알람 설정을 유연하게 변경할 수 있습니다.
- 전문성 활용: 각 도구가 잘하는 부분에 집중할 수 있습니다. Prometheus-Grafana는 다양한 메트릭 수집과 시각화에, AWS CloudWatch는 알람과 AWS 리소스 모니터링에 특화되어 있습니다.
- 비용 효율성: AWS 리소스에 대한 알람만 CloudWatch를 통해 처리하기 때문에, Prometheus의 모니터링 비용과 CloudWatch의 알람 비용을 따로 관리할 수 있습니다.
단점
- 관리 오버헤드: 두 시스템을 따로 설정하고 유지보수해야 하기 때문에 관리에 더 많은 시간이 필요할 수 있습니다.
- 중복 모니터링 위험: 동일한 리소스를 두 시스템에서 중복 모니터링할 경우, 불필요한 알람이 발생할 수 있습니다. 이를 방지하기 위해 모니터링 항목을 명확히 구분해야 합니다.
- 지연 시간: 두 시스템 간의 데이터 전송이 없기 때문에 각각의 시스템에서 발생하는 지연 시간은 용인 가능하더라도, 전체적인 알람 반응 시간에 영향을 줄 수 있습니다.
- 비용: AWS CloudWatch, SNS, Lambda 사용에 따른 추가 비용이 발생할 수 있습니다.
결론
- 용인 가능한 수준: 언급된 단점들은 대부분 용인 가능한 수준입니다. 특히, 관리 오버헤드나 중복 모니터링은 설계와 운영상의 주의로 충분히 관리할 수 있습니다.
- 장점 활용: 설계의 장점을 최대한 활용하면, 보다 신뢰성 있고 유연한 모니터링 및 알람 시스템을 구축할 수 있습니다.
Q : 프로메테우스-그라파나 시스템의 과부화는?
A : 프로메테우스는 대규모 모니터링은 로드밸런서 혹은 샤딩 시스템의 구축을 권장합니다 샤딩은 하나의 프로메테우스가 모니터링할 영역을 나눠 맡는 시스템의 아키텍처로 대규모에는 해당 관리를 권장하지만 우리의 모니터링은 그렇게 많은 리소스가 필요치않다고 판단하여 중규모 관리 시스템인 그라파나와 프로메테우스 둘의 시스템을 독립시키는 방향으로 가게 되었습니다. 향후 시스템의 규모가 더 작아져도 괜찮다고 판단될 경우 소규모 시스템 권장 방향인 하나의 EC2에 그라파나와 프로메테우스를 몰아 설치하는 방법으로 전환될것입니다.
Q : 데이터의 보관은? EC2 용량은 그리 넉넉하지 않지않나?
A : 프로메테우스의 자체적인 롤링과 보관은 사용자 설정에 따라 대부분 다릅니다 별도의 시계열 데이터 베이스 (thanos,InfluxDB,cortex)를 사용하지 않아도 중규모의 모니터링은 자체 내장된 시계열
데이터 베이스로도 충분히 관리가 가능합니다. 이후 누적되는 데이터의 수량,요구사항에 맞추어
추가적인 데이터베이스의 관리가 필요하다 요구되면 전환될 수 있습니다.
(프로메테우스의 공식문서에서는 데이터의 장기보관화와 데이터의 불변성을 필요로하다면 RAID 구성의 저장 설계를 할것을 권장하지만 아니라면 내부 데이터베이스로도 충분하다는 입장입니다)
부연 설명
노드익스포터: 작동하는 서비스의 백그라운드에서 가동하여 현재 시스템의 사용정보를 외부로 전달하는 리눅스 프로그램입니다 바이너리 파일로 구성되어있으며 백그라운드에서 작동합니다
그라파나 : 시계열 데이터를 그래프화 하여 EC2별 , RDS별로 대쉬보드 편집을 하여 보기 쉽게 관리해주는 모니터링 오픈소스입니다 자체적으로는 데이터를 노드익스포터에서 가져 올 수 없습니다.
프로메테우스 : 노드익스포터가 보내온 시계열 데이터를 정리 및 보관하며 일부분 사용자에게 노출 시켜줍니다. 그라파나의 시각화 기능이 강력하여 대부분 노드 익스포터와 그라파나를 이어주는 게이트웨이의 역할로 많이 사용합니다.
실제 뭐..이런 고민들과 설계를 결정하며 그 이유에는 이런것이 있다~ 라고 설명하기 위해 같은 엔지니어들에게 전달할
요량으로 작성하다보니 내용도 좀 지저분하고 그런데 대충 그렇다~ 정도만 이해하면될거같다.
그렇게해서 지금 초안 작업이 마무리되어 가동 중 인 서비스 하나를 테스트로 그라파나까지 연동이 되어 그래프까지 잘나온다
보다 절차적인 방법은 커밍쑨
아마..
'개발 > aws' 카테고리의 다른 글
| aws 카테고리 개설 (0) | 2024.08.14 |
|---|---|
| 프로메테우스 도입기 - 곱뺴기 (0) | 2024.08.01 |